

Mar 24, 2022
I often tell development teams and also technical leadership that Serverless allows a simpler branching and merging strategy and that this will help them deliver code more frequently. In some organisations there is a belief that Scrum prevents the team from deploying multiple times per sprint and that switching to Kanban will solve all their problems. However, there is nothing in the Scrum framework that encourages this practice and I have worked with teams using Scrum that deliver to Production multiple times per day. The only thing in my experience preventing teams achieving this is the poor lead time of their CI/CD process.
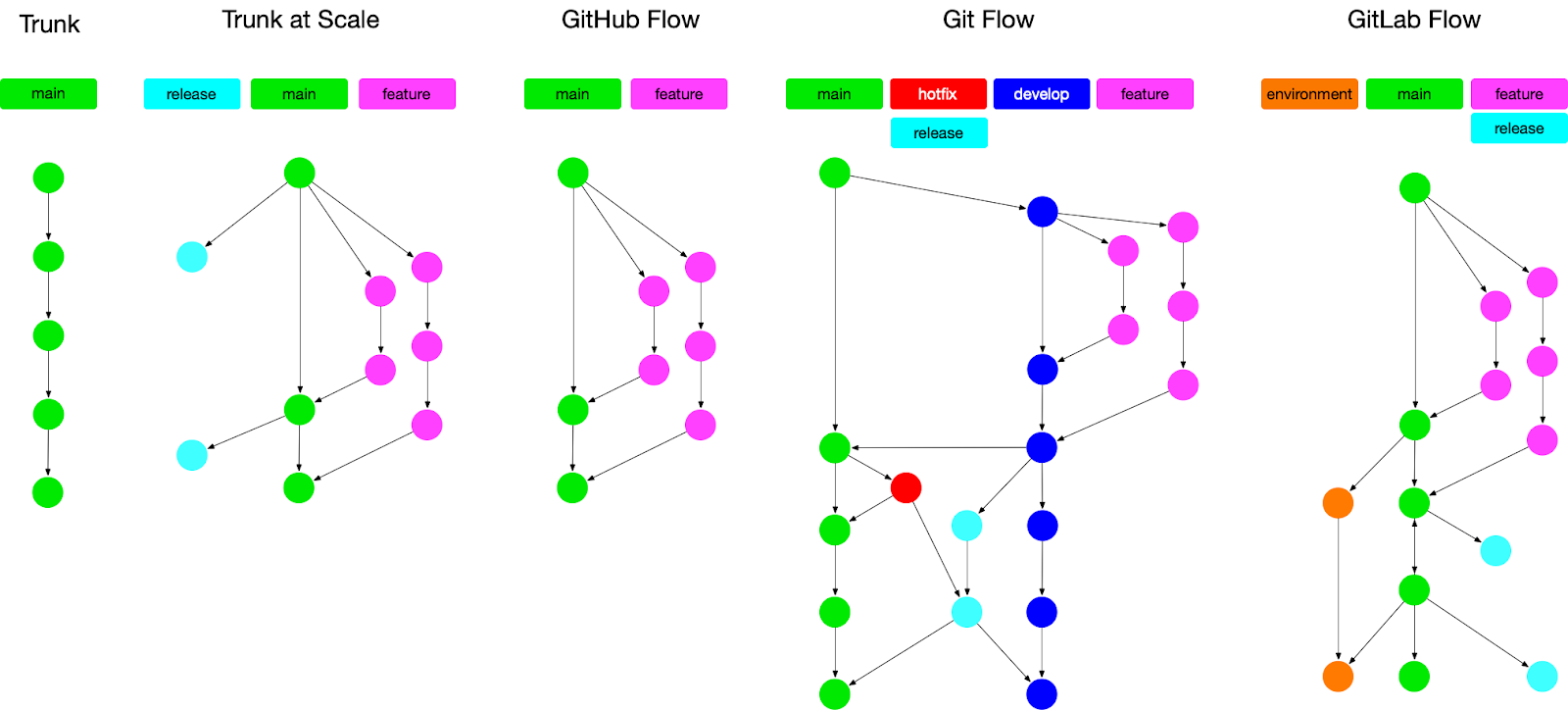
Many teams have chosen to use Git Flow, the most complex of the commonly used Branching and Merging Strategies. In order of decreasing complexity, here are some other flows: GitLab flow, GitHub flow, Trunk-based development (which has a regular version and an “At Scale” version). GitHub flow and Trunk-based development at Scale are very similar.
The case against Git Flow
If you use Git Flow then you have many branches:
- Main branch that represents what you have on Production
- Feature branches
- Develop branch where features are being integrated ahead of being put into a release
- Release Branch where the current release candidate is being tested
- Hotfix branches to work around the fact that the release process is slow\
There is clearly a general point to be made about the complexity of keeping this many open branches and the inevitable merge conflicts. I also want to dig into some of the broader organisational impacts that might not be immediately obvious:
- The existence of a separate Release Branch cements in place the idea of a dedicated Test team or at least a Test role in the development team, which leads to a lack of ownership. In such organisations developers may consider their work done when it has been merged to the develop branch, yet it could still be days from release. I like to think of this technology solution (GitFlow) locking in an organisational boundary (Dev vs Test/QA) as Conway’s Law in reverse and I think ultimately it stops people trying new, more efficient ways of working - which is a real shame.
- Creating a Release Branch and testing each feature it contains is quite a lot of overhead. I typically see teams that use GitFlow only managing to get one release per sprint out of the door. The longer the Release Branch is open, the more chance there is of having to create a hotfix in response to an urgent issue. This puts the pending release on ice while attention is diverted and creates extra complexity in syncing those changes to the Release Branch. In some cases I have seen Test Engineers working a sprint behind the Developers, making a mockery of the Definition of Done and leading to a confused state where nobody knows which features actually made it to Production yet.
So, how did we end up here? In Git Flow the Develop and Release branches exist because we are not confident the code in the Feature Branch is going to work and be free of bugs when merged to the Main Branch. If we can address this issue, then we can massively simplify the process.
Let me explain this claim in more detail: In Git Flow the Develop branch usually corresponds to a Development environment where any integration issues between features are solved. When your feature is fully integrated you can’t merge the Develop branch to main, because in the meantime someone else may have merged their feature to the Develop branch. This is why Release branches are created to freeze the integrated code. If only we could be fully confident in our feature branches, we could merge them directly to the main branch. This is exactly what GitHub Flow is all about.
Serverless + GitHub Flow = Simplicity
To have full confidence to merge directly to the Main branch we need the code from the Feature branch to be verified in an environment that replicates Production as much as possible. This means the full suite of tests must run, including the System or End-to-End tests. We also need this environment to be dedicated to our feature otherwise we will have conflicts with other developers.
It is not common practice to have an environment per Feature Branch in provisioned-capacity architectures (e.g. containers) because it is expensive, however Serverless completely changes the game. A Serverless environment can be set up rapidly using on-demand pricing and the cost will be negligible. In our Serverless teams we have a new environment spun up by the CI/CD pipeline every time a branch is created in Git and have a cleanup task that automatically tears these environments down after it is merged to the main branch. A typical development and testing workflow looks something like this:
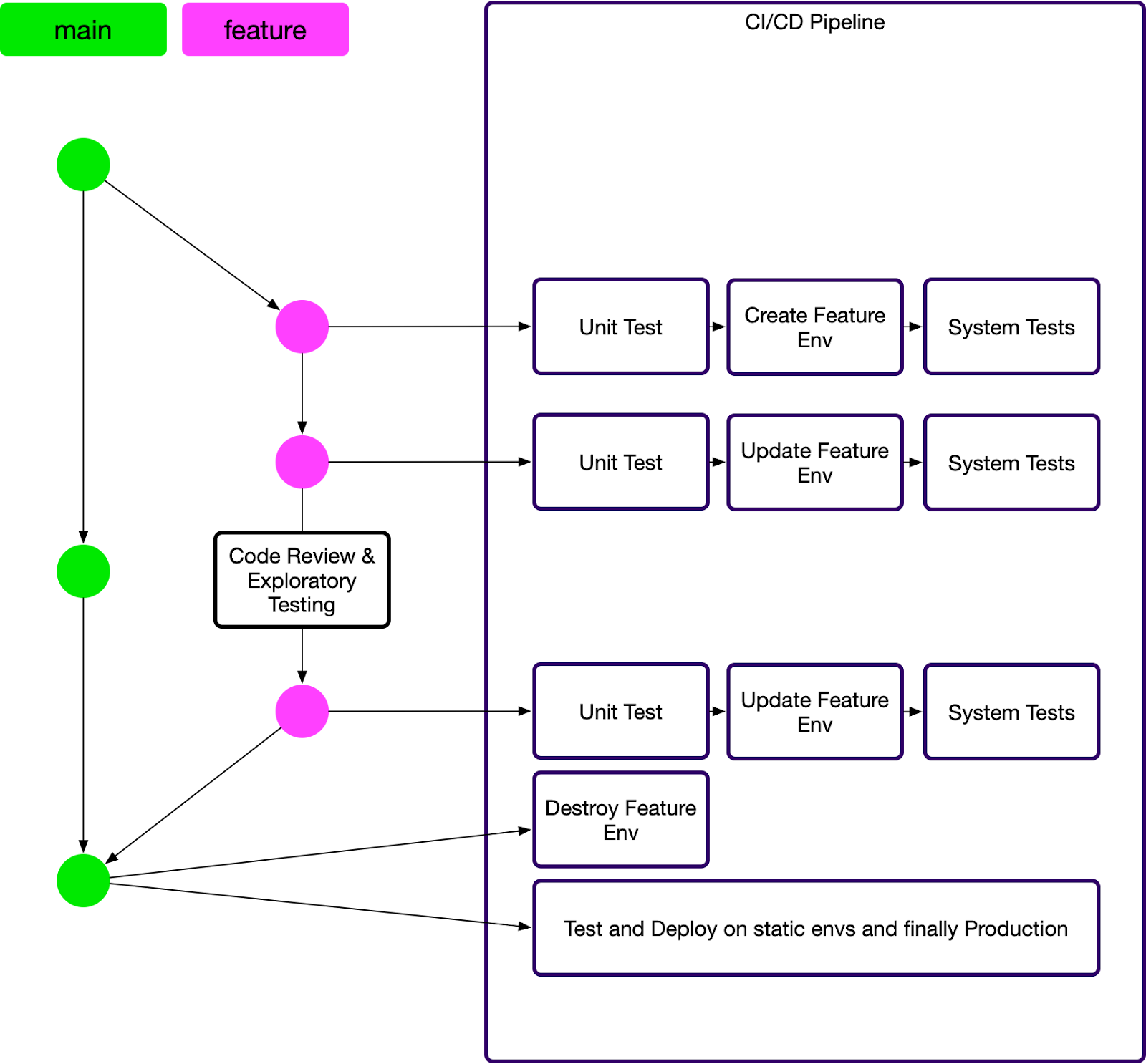
- Create new feature branch from Main
- Write new feature code and Unit Tests
- Commit and push to new branch in Git
- Verify the build is green (Unit Tests passed and environment is deployed)
- Execute manual exploratory testing on the Feature Branch environment
- Write System Tests, calling real endpoints on the Feature Branch environment from the tests running locally
- Commit the code for the System Tests and push to Git
- Verify the build is green (System Tests passed)
- Open Pull Request
When using this workflow the feature is already fully integrated and tested on a real environment in the Cloud at the point the Pull Request (PR) is opened. If subsequent commits on the main branch create a conflict the developer is asked to update their branch and fix the conflict. It will not be possible to merge the PR if there are conflicts, if any of the tests fail, or of course if there are not enough reviewers. For a typical team requiring 2 approvers for each PR, only Developers are needed to get this feature to Production and this whole process can be done for a small feature in a matter of hours. For an urgent fix I have seen it done in 15 mins.
Local environments
Another consequence of this way of working is that local development environments become obsolete. I have seen many teams struggle to maintain a working local development environment with mocks for the various cloud services they use and there are usually unforeseen issues when deploying code developed in this way to the Cloud. Having a fully featured Cloud environment per feature gives each developer their own private sandbox. Creating and destroying these environments automatically from the CI/CD pipeline means developer accounts are conveniently cleaned up and always fresh for every new feature.
TODO: DIagram for above
Dedicated Test Teams
If your organisation has dedicated test teams or dedicated Test Engineers in your development teams, you can still migrate to this way of working without making people feel devalued or scared about their future. It is possible to have a team of generalist developers each having their own specialist area of knowledge, whether that is NoSQL single-table database design, React state management or Browser-based UI test automation. In such a team we expect everyone to know a little bit of everything and to try their hand at writing code in all parts of the application, knowing they can seek help from experts in their team when they need it. Sharing knowledge makes the team more flexible and resilient and advances career development.
When a Test Engineer moves from an external test team into the development team the organisation should support them as they expand their knowledge to include feature development. This could include dedicated time for training and pair programming with experienced developers.
In some organisations testing may be extremely complicated, for example when custom hardware is required to run the software under test. In this case the test team could become a development team whose Product is a test framework for the other teams to use. This maintains the concept of self-organising teams, assuming teams do not get blocked waiting for new features in the test framework. However, even when using a standard open source test framework this can happen and teams are already accustomed to creating workarounds or even committing a fix themselves. This approach can be replicated in an organisation using the Inner Source model, with one maintaining team and many teams contributing.
Final words
So let’s recap on the benefits of going Serverless and switching to Github Flow:
- Shorter lead time to get features on production
- Release multiple times per sprint
- Create truly self-organising teams by giving developers the power to deploy all the way through to Production
- Remove the overhead of developing against local stacks that simulate cloud dependencies
- Generalist teams are more flexible and resilient