

Jun 21, 2023
Previously (TODO: link to "beyond monorepo" article), we discussed structuring real-life serverless projects. One sure thing is those projects will contain multiple CloudFormation stacks. Furthermore, those stacks will depend on each other and need to share parameters - names and ARNs of resources created in one stack to be used in another stack.
Here we will review three ways to pass such parameters between the CloudFormation stacks, microservices, and AWS accounts. We will have a strict way, a static way, and a dynamic way.
Need for sharing parameters
Serverless and microservice applications in general consist of multiple deployable units - stacks. Those stacks are managed with IaC tools like CloudFormation. You can use CloudFormation directly or with higher-level tools built on top of it: Serverless Framework, SAM, or CDK. No matter what you choose, those stacks have dependencies on each other.
Let's take an e-commerce application as an example. It will have a Store service communicating with the Catalog, Orders, and Payments. Therefore, the Store is dependent on those three.
Firstly, the Store service needs to know the API endpoints of the other services to communicate. This is relatively easy to solve with good old domain names. In the Store service, you can hardcode the Catalog URL, let's say catalog.example.com. For non-prod environments, it can use a subdomain matching its own environment name: on "staging" call staging.catalog.example.com, on "preprod" call preprod.catalog.example.com, and so on.
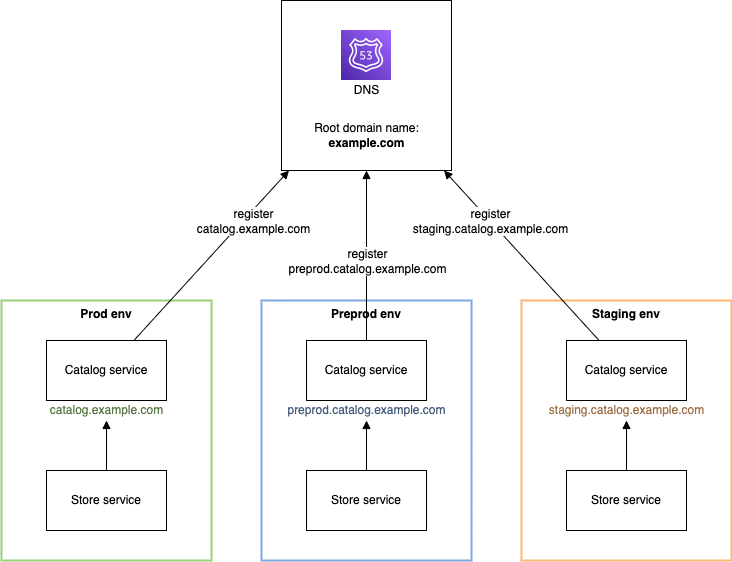
With domains, the deployment order doesn't matter. The Store just needs to handle 404 errors if the Catalog is not (yet) available. The overhead of registering a subdomain for each service and environment is minimal after it's configured once.
But even with an API endpoint, you may need additional parameters. Since that is an internal API, it will be protected best with IAM authorization. For this purpose, you create an IAM role in the Catalog service that the Store service can assume and use to sign the requests.
To hardcode or not
You could argue that for the IAM role names, you can use the same strategy as with the domain names. Make the naming predictable and hardcode it on the client-side. For instance, the role name could be catalog-prod-storeClientRole, and similar for other environments.
However, there are a few flaws in this approach. Firstly, each resource like this is effectively blocked from any name changes, even if it's internal and not exposed to any 3-rd party consumers. Secondly, if you modify the name, you need to change it in two places - in the Catalog service that owns it and the Store service that uses it. And lastly, hardcoding resource names in the CloudFormation is generally a bad idea. Instead, CloudFormation can generate a unique name with a random suffix on its own. This can save you from problems like non-unique or invalid names. Also, the hardcoded name makes updates that require resource replacement impossible without changing the name.
Yet another case is the parameter value generated by the AWS that we can't set on our own. Even in the scope of the same microservice, you may need to pass such value from one stack to another. An example can be the Amazon Cognito Identity Pool ID generated during the resource creation.
Ways of sharing parameters
We know now that we can't escape from passing the parameters from one stack or service to another. There are three primary ways of sharing values on AWS:
- CloudFormation Outputs
- Systems Manager Parameter Store (SSM)
- Secrets Manager
Since the Secrets Manager is similar to the SSM in how it works, let's focus on the CloudFormation Outputs and SSM.
Hard dependencies with CloudFormation Outputs
You can share resource names and ARNs by defining them as CloudFormation Outputs with an Export flag. Then you can reference it in another stack using the Fn::ImportValue intrinsic CloudFormation function.
catalog-stack.yml:
AWSTemplateFormatVersion: '2010-09-09'
Resources:
HttpApi:
Type: AWS::ApiGatewayV2::Api
Properties:
ProtocolType: HTTP
Outputs:
ApiEndpoint:
Value: !GetAtt HttpApi.ApiEndpoint
Export:
Name: !Sub '${AWS::StackName}-ApiEndpoint'store-stack.yml:
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
CatalogStackNameParameter:
Type: String
Resources:
MyLambda:
Type: AWS::Lambda::Function
Properties:
Runtime: nodejs14.x
Environment:
Variables:
CATALOG_API_ENDPOINT: !ImportValue
'Fn::Sub': '${CatalogStackNameParameter}-ApiEndpoint'But there is a catch. Well, actually more than one. Following the docs:
- For each AWS account,
Exportnames must be unique within a region. - You can't create cross-stack references across regions. You can use the intrinsic function
Fn::ImportValueto import only values that have been exported within the same region. - For outputs, the value of the
Nameproperty of anExportcan't useReforGetAttfunctions that depend on a resource. - Similarly, the
ImportValuefunction can't includeReforGetAttfunctions that depend on a resource. - You can't delete a stack if another stack references one of its outputs.
- You can't modify or remove an output value that is referenced by another stack.
As you can see, there are quite a few restrictions. Most of them prevent you from altering the exported output value if any other stack uses it.
Initially, that seems to make sense. You don't want the Catalog service to be removed (together with exported parameters) since the Store service relies on it, right?
Well, not always.
Disadvantages of strict references
Take the development environment as an example. If you create an environment for the feature branch testing, which is later removed on the branch merge, it doesn't really matter if you remove the Catalog service first. You just want to purge everything.
But this is a development environment. What you care about is the production environment stability.
However, this hard protection can backfire easily on the production too.
Suppose you find a problem in the cross-service communication that you need to fix quickly, and it requires deploying a new IAM Role. In that case, this protection can prolong the issue resolution. Instead of deploying the Catalog service with a new resource and then deploying the Store service to use it, you need an additional step of updating the Store to stop using the old parameter first.
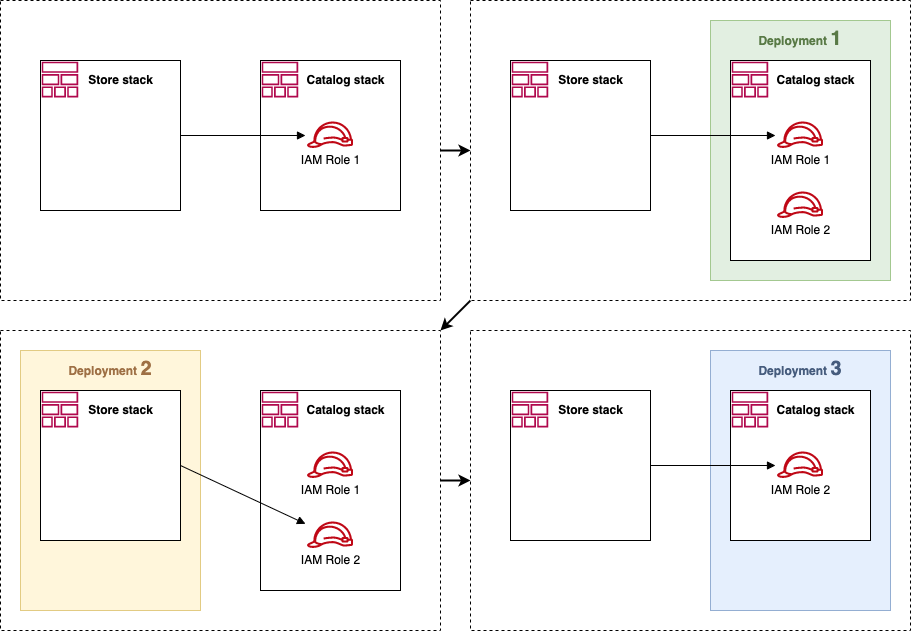
Similarly, deploying two stacks together as part of the same microservice, you may accept a few seconds of downtime when the updated resources and new parameters are rolled out. But the CloudFormation does not. So, again, you need to make every change in two steps. First, add new resources, then remove the old ones. Again, this may be good on production, not necessary anywhere else. The two commits must be deployed separately, one by one. But after they are merged to main, everyone else who pulls them to their own branch/environment will end up with deployment errors and hate you.
Inability to use CloudFormation outputs cross-region is a whole different kind of an issue potentially preventing you from using it to share parameters altogether.
Outputs with nested stacks
CloudFormation Outputs can also be used to pass parameters between nested stacks. In that case, you don't need to Export them. This relaxes some restrictions, like the name needing to be unique within a region.
On the other hand, those are still strict references, and they come with the same drawbacks.
Soft dependencies with SSM
Another way of sharing values is using the Systems Manager Parameter Store, better known as SSM. You create an SSM parameter in one stack and fetch it during the deployment of the second one.
You can achieve this in pure CloudFormation, as well as in SAM, Serverless Framework, and CDK. In fact, Serverless Framework and CDK handle SSM parameters on their own and pass the resolved values to the CloudFormation template to provide more flexibility.
An example with CloudFormation:
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
CatalogApiEndpointParameter:
Type: AWS::SSM::Parameter::Value<String>
Default: '/catalog/apiEndpoint'
Resources:
MyLambda:
Type: AWS::Lambda::Function
Properties:
Runtime: nodejs14.x
Environment:
Variables:
CATALOG_API_ENDPOINT: !Ref CatalogApiEndpointParameterAnd the same with Serverless Framework:
service: store
provider:
name: aws
runtime: nodejs14.x
functions:
myLambda:
handler: index.handler
environment:
CATALOG_API_ENDPOINT: ${ssm:/catalog/apiEndpoint}Using SSM instead of CloudFormation Outputs has several advantages:
- No limitations on the SSM parameter name as with CloudFormation Outputs.
- No restrictions on modifying or deleting existing parameters.
- In Serverless Framework, the ability to reference SSM parameters from other regions (and maybe someday in CDK too).
Of course, you can see the lack of protection of the parameters used by other stacks as a drawback. Yes, it requires thinking about usage and consequences every time you want to change an existing parameter. But, on the other hand, it allows you to move forward quicker, without the restrictions being more of an obstruction than help.
Fallback to default parameter
There is one little trick to reducing development complexity in microservice projects.
If a service is referencing another, by the rule, it should take the parameter value for the same environment as its own. So, for example, in the Store service on "prod" environment, you should fetch the IAM role name for the "prod" environment of the Catalog service as well. And likewise in other environments.
This requires every developer working on their own environment to have both the Store and Catalog services deployed and kept up to date. As well as probably many more services.
However, if you work only on the Store service and do not deploy any changes to the Catalog, you could use a common Catalog service that is kept up to date. For that reason, to reduce the number of deployments and maintenance work for developers, we usually use this pattern:
- on "prod" environment, reference parameters from "prod"
- on "staging" environment, reference parameters from "staging"
- on "test" environment, reference parameters from "test"
- on other environments, reference parameters from the same environment name, and if it does not exist, from the "test"
This is how it looks like in Serverless Framework v3:
service: store
params:
prod:
targetEnv: prod
staging:
targetEnv: staging
default:
targetEnv: test
custom:
catalogApiEndpoint: ${ssm:/catalog/${sls:stage}/apiEndpoint, ssm:/catalog/${param:targetEnv}/apiEndpoint}
provider:
name: aws
runtime: nodejs14.x
functions:
myLambda:
handler: index.handler
environment:
CATALOG_API_ENDPOINT: ${self:custom.catalogApiEndpoint}As a result, every developer works in their own separate environment for the services they modify but does not have to deploy all other services in the project.
Dynamic dependencies with SSM
The two previous methods, CloudFormation Outputs and SSM, were deployment-time. This means that the parameter values were resolved during the deployment and then effectively hardcoded into our stack resources - for example, Lambda function environment variables.
Due to this, if we modify the parameter in the Catalog service, we need to re-deploy the Store service to update it and start using the new value.
This is fine in most cases. But what if we need the Store to update the parameter value without a re-deployment? The solution is to keep parameters in SSM but read them in runtime instead of during the deployment.
Of course, calling SSM to get the latest parameter version on every incoming user request is not the best idea. It increases latency and may cause errors by hitting the SSM throughput quotas on a bigger scale. So the value should be cached in memory until it reaches expiration timeout.
import {ssmParameter} from 'aws-parameter-cache';
const catalogApiEndpointParam = ssmParameter({
name: '/catalog/apiEndpoint',
maxAge: 1000 * 60 * 5, // 5 minutes
});
export const handler = async () => {
const catalogApiEndpoint = await catalogApiEndpointParam.value;
};A more advanced solution could include refreshing the value on error. For example, if the parameter is the IAM role name and our authorization fails, we can invalidate the cached value and fetch it again. However, we should be careful not to flood the downstream service with invalid requests if it's not the IAM role name the problem here. This could be done by implementing a Circuit Breaker pattern.
Cross-account parameters
There is another advantage of resolving parameters in the runtime. We can make cross-account calls to get parameters from other AWS accounts with this approach.
This is helpful when our services are deployed across multiple AWS accounts.
import {AssumeRoleCommand, STSClient} from '@aws-sdk/client-sts';
import {GetParameterCommand, SSMClient} from '@aws-sdk/client-ssm';
import {Credentials} from '@aws-sdk/types';
export const handler = async () => {
const catalogSSMCredentials = await getCatalogSSMCredentials();
const catalogApiEndpoint = await getCatalogApiEndpoint(catalogSSMCredentials);
};
const getCatalogSSMCredentials = async (): Promise<Credentials> => {
const sts = new STSClient({});
const response = await sts.send(new AssumeRoleCommand({
DurationSeconds: 3600,
RoleArn: process.env.CATALOG_SSM_ROLE_ARN,
RoleSessionName: 'awssdk',
}));
if (!response.Credentials) {
throw new Error('Cannot retrieve credentials');
}
return {
accessKeyId: response.Credentials.AccessKeyId,
secretAccessKey: response.Credentials.SecretAccessKey,
sessionToken: response.Credentials.SessionToken,
expiration: response.Credentials.Expiration,
};
};
const getCatalogApiEndpoint = async (credentials: Credentials): Promise<string> => {
const catalogSSM = new SSMClient({
credentials: credentials,
});
const response = await catalogSSM.send(new GetParameterCommand({
Name: '/catalog/apiEndpoint',
}));
if (!response.Parameter?.Value) {
throw new Error(`Cannot retrieve parameter ${paramName}`);
}
return response.Parameter.Value;
};Summary
As we discussed, some parameters must be shared between the CloudFormation stacks. There are three main ways to achieve this. One is to use CloudFormation Outputs, which is the default solution. However, it has many drawbacks. A more flexible way is to save parameters in SSM. Then we can obtain them either during the deployment or in the runtime. Fetching SSM parameters in the runtime, despite adding complexity, has two additional benefits. This way, we can refresh parameter values without re-deploying the stack and fetch parameters from other AWS accounts.
Using SSM for sharing parameters between CloudFormation stacks is a pattern that we successfully use across multiple projects. Depending on the use case, we either resolve them during the deployment or in runtime.