

Mar 24, 2022
Building serverless applications require our projects to be well architected and scalable. While we often think about scalability in terms of the throughput, it's also crucial that projects scale up in terms of the development when they grow and more people and teams work on them.
Here I describe how we structure real-life serverless projects, apply architecture design principles, and make trade-offs when necessary.
Monorepo - a perfect fit for serverless
Before we go beyond monorepo, let's start with the monorepo itself.
Serverless has many advantages, and a short developer feedback loop - how fast can we run and verify the code change - is one of them. You don't have to build, deploy, and launch a whole massive application to test it. Instead, you only modify a small Lambda function.
But serverless projects are more than just one Lambda function. They are composed of multiple resources, like APIs, SQS queues, DynamoDB tables, S3 buckets, etc. In fact, a serverless project can contain dozens of resources, and there is nothing wrong with it.
However, if we put all of them in a single unit of deployment, let's say CloudFormation stack, we will face several problems:
- Limit of resources in a single CloudFormation stack
- Long time it takes to (re)deploy the stack or rollback changes in case of errors
- Often merge conflicts on a single stack
While the first was more of a problem before the stack resources quota was raised to 500, the others are still valid. The more resources in the stack, the longer each operation will take. In addition, working on the same piece of infrastructure code by multiple developers leads to conflicts that must be resolved. All of this extends the feedback loop and decreases the Developer Experience.
The solution? A monorepo with multiple stacks.
Splitting service into stacks
Let's imagine a simple serverless store service. We need to host the website, allow users to authenticate through Cognito, and let them browse and order products. For this purpose, we will use AppSync API with Elasticsearch database for products and DynamoDB table for orders.
The architecture could look like this:
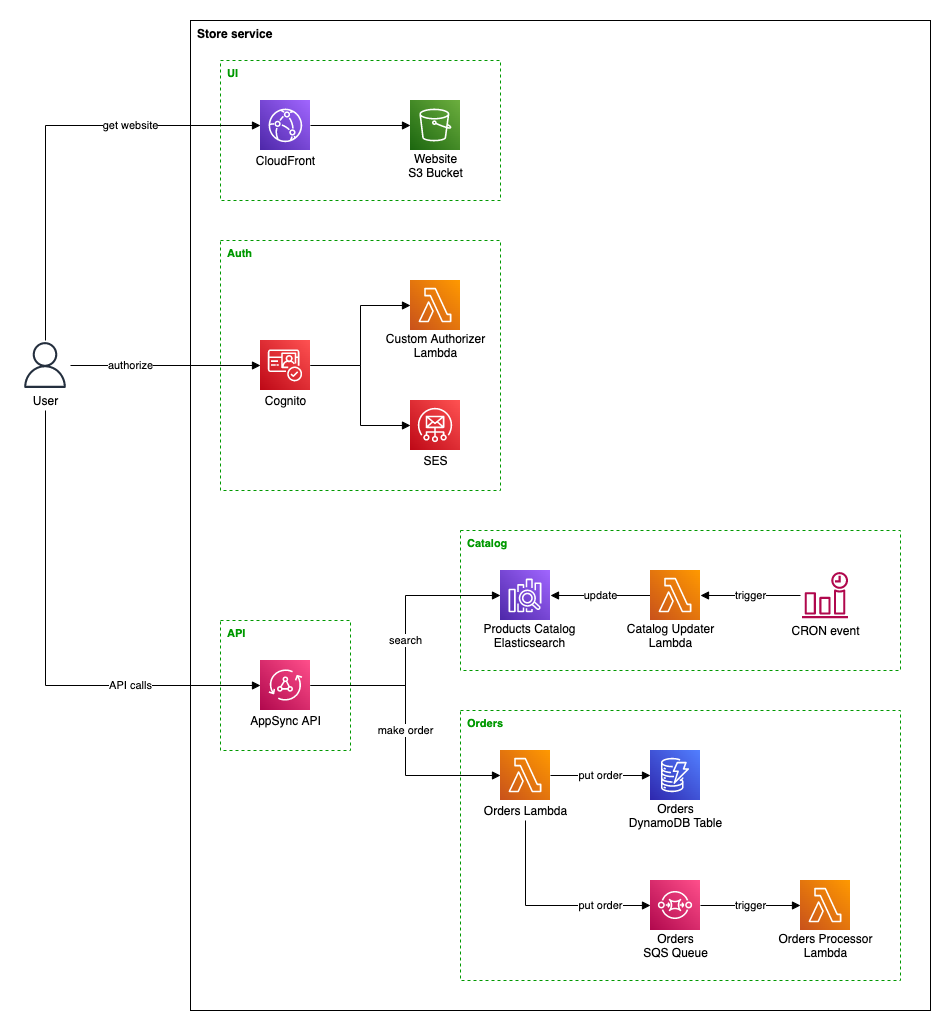
As you can see, this relatively straightforward service is comprised of a dozen pieces, not to mention that most of them require creating multiple resources. For example, the Lambda function requires IAM Role and CloudWatch Log Group, the AppSync consists of multiple Data Sources and Resolvers, and so on.
We can split this service into several stacks, as marked on the diagram: UI, Auth, API, Catalog, and Orders. The same structure would be visible in the repository organization:
store-service
├── README.md
└── stacks
├── api
│ └── stack.json
├── auth
│ ├── src
│ │ └── authorizer.ts
│ └── stack.json
├── catalog
│ ├── src
│ │ └── updater.ts
│ └── stack.json
├── orders
│ ├── src
│ │ ├── orders.ts
│ │ └── processor.ts
│ └── stack.json
└── ui
└── stack.json
When working on the service, initially, you have to deploy all the stacks to create your own development environment. But then, after modifying a single Lambda function or another piece, you have to re-deploy only the one stack that contains it. Furthermore, because each stack corresponds to a single feature, you will most likely work on a single stack to implement new business requirements and changes.
Managing monorepo
With monorepo, you need a way to execute commands, like deployment, on all the stacks. While you can do it with a simple bash script, a much better option is to use a dedicated tool. Such tool will provide you with additional features out-of-the-box, such as:
- parallelization
- dependencies management
- selective deployment
Deploying stacks in parallel reduces overall deployment time.
However, stacks in a single service can have dependencies on each other. For instance, in our Store service, the API stack with AppSync requires the Catalog and Orders stacks to be deployed first. Only then can we reference the Elasticsearch database and Lambda function in AppSync resolvers. Therefore, we need our tool to understand and respect these dependencies while still parallelizing deployment wherever possible.
And finally, we may have stacks that we don't want to deploy to each environment. Most often, those are stacks with mocked external services. We use them in development environments, but we don't want to have them in production.
Two monorepo management tools that we use are Lerna and Nx. Both are Node.js tools.
Lerna
For Lerna, everything needed is specified in package.json files of individual stacks:
{
"name": "@store/api",
"scripts": {
"deploy": "sls deploy",
"remove": "sls remove"
},
"dependencies": {
"@store/catalog": "1.0.0",
"@store/orders": "1.0.0"
}
}
Then we can run the deployment from the root service directory with:
lerna run deploy --stream --ignore '@store/*-mock'
It will simply execute the deploy command for each stack, in parallel where possible, omitting all the stacks with the name ending with -mock.
Nx
For Nx, we need to specify an implicit dependency in the project.json of the individual package:
{
"root": "packages/api",
"sourceRoot": "packages/api/src",
"projectType": "library",
"implicitDependencies": ["catalog", "orders"]
}
Then we can run the deployment. To omit mock packages, we use deployProd target that is defined only for packages we want to have on the production:
nx run-many --target=deployProd --all
Serverless project - a collection of services
Our serverless store is successful. Components scale automatically to handle growing traffic so we can focus on adding more features. Now we need to provide a way for employees to manage products.
While our runtime scales up automatically, our development and deployment pipelines do not. Putting more and more stacks in the existing service would give us all the same problems we wanted to avoid with separate CloudFormation stacks. We would start hitting various AWS quotas when deploying everything at once, and the deployment would take longer and longer. More and more people working on the same codebase would make the code ownership fuzzy and tracking and reviewing changes hard.
So for the same reason that we split resources into separate stacks, we split stacks into separate repositories.
Our Catalog management panel will be a separate website. Since it's not related to the main store UI and intended just for the employees, we will also use a separate Cognito for authorization.
After extracting the Catalog as a separate service, the architecture could look like this:
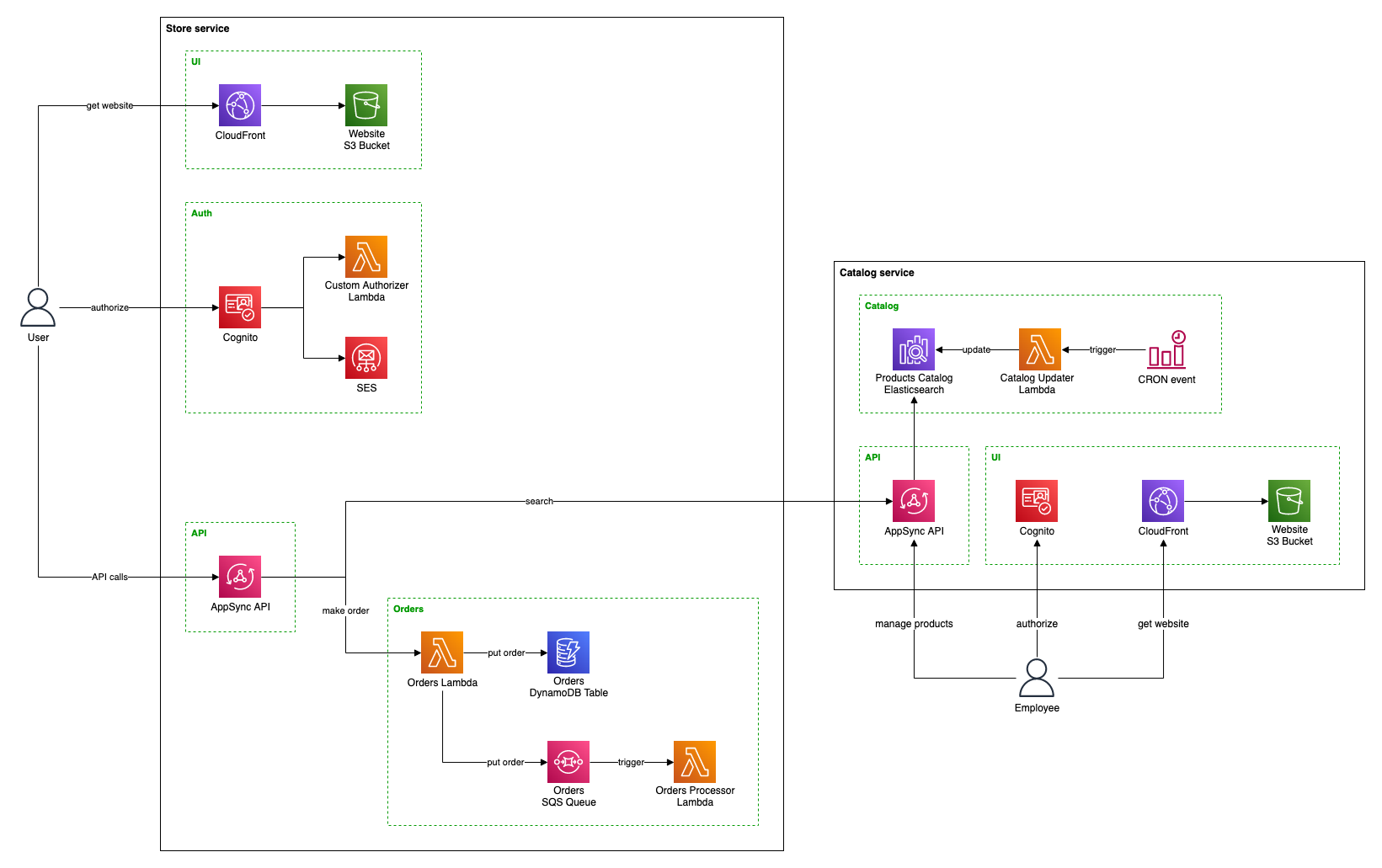
Services of a single project can be deployed to the same or different AWS accounts. We, however, prefer to deploy them all to the same account to simplify organization and per-project cost monitoring.
As a result, our project has a four-level structure:

Serverless services are microservices
If we abstract the architecture diagram a little bit and add one or two more services, a somehow familiar image will come to life:
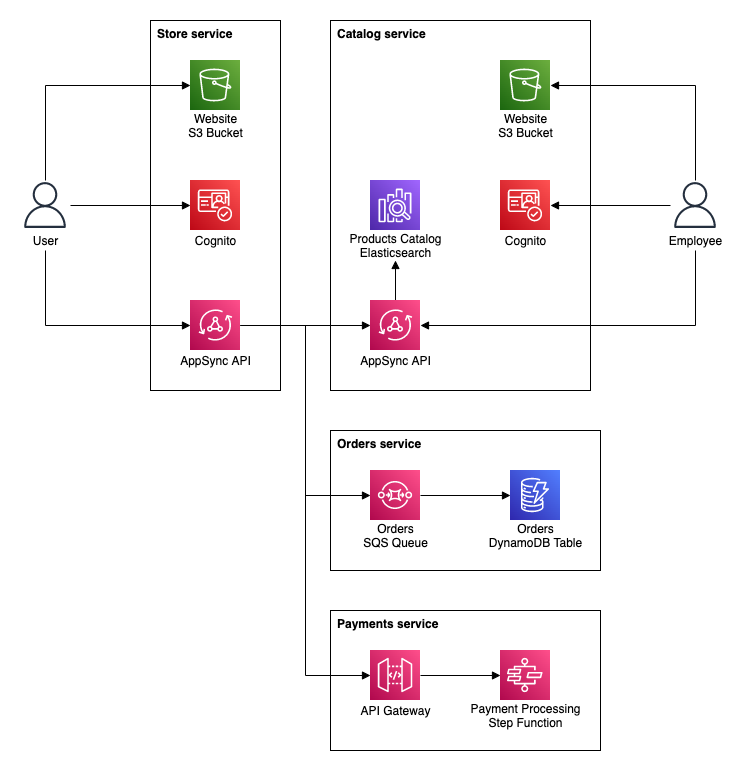
It's nothing else than microservice architecture. In fact, each of our services is a microservice, with a separate codebase, narrowed responsibility, and potentially an independent team developing and maintaining it.
Internal resources - service vs. stack
Knowing that our services are microservices helps us greatly with architecture design. After all, we have a vast collection of microservice designs patterns at our disposal.
One of the rules of microservice design is encapsulation. Similar to OOP, internal logic and resources should be hidden from the outside world. Another is a loose coupling - not relying on the same resources, so microservices can be developed, changed, and deployed independently. So how does this translate to our four-level structure?
We established that the service (monorepo) in our structure is a microservice. Therefore, everything in the monorepo is either internal microservice resources or an API exposed for the communication.
While stacks inside a single service should follow the single responsibility principle to ease and speed up the development, the microservice separation rules do not apply to them. As mentioned before, we can have dependencies between the stacks. We can also directly use resources from other stacks.
A good illustration of this is a database. There is a general consensus of using a separate database per service. With this in mind, we can create a stack in our service with a DynamoDB table. Other stacks can have Lambda functions reading and writing to this table. We just need to ensure the stack with DynamoDB is deployed first before stacks with Lambda functions that use it. However, this DynamoDB table is internal to the service. Thus, other services should not access it directly but through the service API.
Cross-service communication - (not only) by API
This way, we touch on another bit of microservices design - communication.
As explained above, loose coupling makes us hide the database and other internal resources from other services. Usually, we hide them behind an API. Most commonly, it's a REST with API Gateway or GraphQL with AppSync.
But REST and GraphQL are not the only possible connection points for cross-service communication.
Instead, we can expose messaging services endpoints. An SQS queue or Kinesis stream can act as a data ingestion interface for our service. Moreover, for the communication spanning across the whole application, we can use EventBridge.
Hiding messaging behind API
With SQS, Kinesis, and EventBridge being AWS-specific services, you could argue that exposing them exposes internal service resources, thus breaking the encapsulation and introducing tight coupling since we can't transparently replace those resources with anything else.
And yes, I agree. Yet, programming is the art of making compromises.
In this case, we must make a compromise between the tight coupling and operational costs.
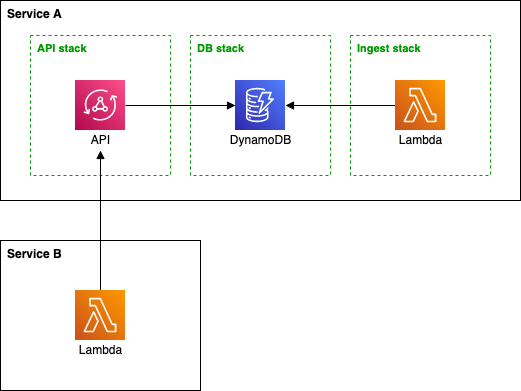
.png?width=551&name=2021-11-serverless-project-structure-messaging%20api.drawio%20(2).png)
As you can see in service A, we can hide the messaging service behind the API. API Gateway and Ingest Lambda can perform custom authorization, validate and transform the message, and push it to the queue. We can change the internal format of the message, replace the SQS with Kinesis, but keep the client-facing API the same.
In contrast, service B exposes the SQS queue directly. That means the client, Process A Lambda, can only use IAM authorization. But it can write anything to the queue. We must validate data on the consumer side in Process B Lambda. However, we do not pay for the API Gateway and Ingest Lambda function executions. With high throughput, this may be a significant saving.
So how to balance this out, and what decision make? The answer is on the diagram above.
For the client-facing services, be it a frontend, mobile application, or external system, hiding implementation details is paramount. If we decide to replace the SQS with Kinesis, we are not dependent on a separate application to be updated.
On the other hand, the coupling constraints of internal cross-service communication can be more relaxed. Especially if we are in charge of both the producer and the consumer, potential migration is doable without widespread work synchronization taking months to roll out.
Yet another case is EventBridge. It was created specifically for cross-service communication. Therefore, it's intended to be used directly, as a central event bus, without additional APIs standing in front of it.
Final thoughts
The four-level structure - project, service, stack, resource - gives flexibility to the teams to develop fast while keeping the architecture clean and maintainable. While building serverless microservices, we apply well-known architecture patterns. That results in projects being scalable in terms of not only the throughput but also development.
Another important bit of building serverless on AWS is sharing configuration and parameters between the services and stacks. We will cover this in the next post.