

Jan 29, 2019
After designing and learning a ML model, the hardest part is actually running and maintaining it in production. AWS is offering to host and deploy models via On-Demand ML Hosting on various instance types and sizes, packaged as the SageMaker service. These start with a ml.t2.medium and go up to GPU accelerated ml.p3.16xlarge instances.
To stay serverless in an already serverless deployment and also to keep costs low and allow for flexible scaling, a pure AWS Lambda based ML model inference is desirable. Such approaches exist and have already been described elsewhere, but have some caveats, like running via a REST interface and an API Gateway endpoint. In a bigger Lambda and step functions production deployment it is possible just to invoke a pure Lambda event triggered flow without the REST and API gateway detour. Since a lot of AI and ML tooling is based on Python and uses Python based tools like scikit-learn, a Python based Lambda runtime is chosen.
Towards the end of this post a cost comparison between such a serverless approach and the traditional hosting approach is presented.

This diagram shows a specific ML flow in a larger data processing pipeline. Data and documents are decomposed and written to a DynamoDB table, and the changes are placed in a DynamoDB data stream for multiple downstream consumers. In reality it is a bit more complex, due to general processing limitations and a fan-out pattern is used, more generic details are described in this AWS blog post “How to perform ordered data replication between applications by using Amazon DynamoDB Streams”.
Table of Contents
- Generate and save the ML model
- Build the ML inference Lambda Function
- AWS Lambda Layers
- Layer 1: Build and publish the Dependencies layer with docker
- Layer 2: Publish the model and preprocessor layer
- Function layer: Generate and publish the function
- Link the layers
- Update (only) the model layers
- Execution and cost observations
- Execution time
- Execution cost
- Conclusion
Generate and save the ML model
The model was created via Jupyter notebooks and utilises scikit. Since the input data is text based, NLP (Natural Language Processing) techniques were used. To save and persist the trained model, scikit offers (de)serialization of models containing large data arrays via the Joblib function.
from sklearn.externals import joblib
# Save to file in the current working directory
joblib_file = “MyModel20190104v1.joblib”
joblib.dump(model, joblib_file)
# Load from file
joblib_model = joblib.load(joblib_file)
Using saved models in such a way requires attention to the following points:
- The underlying Python version. The same major version of Python should be used to deserialize the model as was used to save/serialize it.
- Library Versions. The versions of all major libraries used during the model generation should be the same when deserializing a saved model. This is mainly applicable to the version of NumPy and the version of scikit-learn. Additionally if a different OS is used to build the model, it is important that natively compiled C programs are suitable for the AWS Lambda runtime.
Build the ML inference Lambda Function
Taking the above requirements into account the ML Lambda function can be built and deployed. To allow an easy life-cycle management of the underlying model and easy updates when the model is optimized or adapted further to the new data sets, AWS Lambda Layers, introduced at re:Invent 2018 will be used.
AWS Lambda Layers
With AWS Lambda Layers it is possible to separate different parts and dependencies of the code and therefore it is not necessary to upload all artefacts and dependencies on every change.
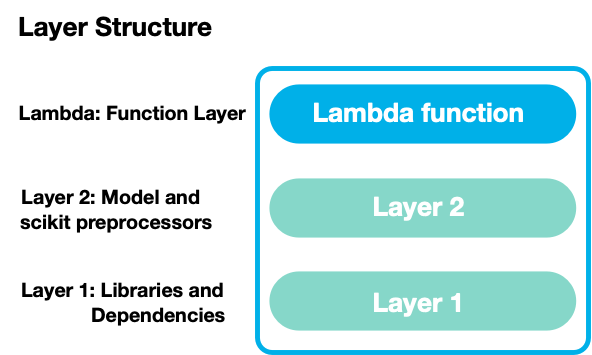
Now it is also possible to create a fully custom runtime that supports any programming language, which might be a next step for the runtime optimization of the ML inference lambda (See later section regarding invocation times).
Layer 1: Build and publish the Dependencies layer with docker
It is assumed that a virtual environment has already been created (in this case with pipenv) with the right Python version (the environment in which the model tuning and design was done). The accompanying requirements file can be created with:
pipenv lock -r > requirements.txt
To have a certain Python version and also the matching AWS lambda runtime, the dependencies are built via a docker container from the LambCI project.
The following script get-layer-package.sh can be executed to generate the dependencies:
#!/bin/bashexport PKG_DIR="python"rm -rf ${PKG_DIR} && mkdir -p ${PKG_DIR}docker run --rm -v $(pwd):/foo -w /foo lambci/lambda:build-python3.6 \pip install -r requirements.txt --no-deps -t ${PKG_DIR}
All the dependencies will be exported into the Python folder in the virtual environment. The directory structure and files have to be zipped to be ready for upload:
zip -r MyMLfunction_layer1.zip python
The generated zip package can be uploaded directly if the size doesn’t exceed 50MB, which is most likely in this case. Additionally there is a limit regarding the total size of a layer which is around 250MB. Therefore we first do an upload to S3:
aws s3 cp MyMLfunction_layer1.zip s3://mybucket/layers/
And then immediately publish the layer:
aws lambda publish-layer-version --layer-name MyMLfunction_layer1 --content S3Bucket=mybucket,S3Key=layers/MyMLfunction_layer1.zip --compatible-runtimes python3.6
Layer 2: Publish the model and preprocessor layer
For our specific model we have two pre-processors and the model saved in the virtual environment, all with the file extension .joblib .
$ ls *.joblib
PreProc1_MyModel.joblib
PreProc2_MyModel.joblib
MyModel.joblib
These files have to be zipped and then published as the additional layer. Here we do a direct upload, since the layer is only a few MB in size:
zip MyMLfunction_layer2_model20190104v1.zip *.joblib
aws lambda publish-layer-version --layer-name MyMLfunction_layer2 --zip-file fileb://MyMLfunction_layer2_model20190104v1.zip --compatible-runtimes python3.6
It is very important for the later loading within the Lambda runtime, that these files are available in the mounted /opt directory in the Lambda container.
Having this additional layer containing only the model allows us to easily publish a new version of the model later on.
Function layer: Generate and publish the function
The lambda function has to read the data from the Kinesis stream and then perform a prediction using the loaded model. It is triggered via the Kinesis events and defined batch size (Set in the lambda configuration for the Kinesis event). The bellow lambda_function.py reads all relevant text data and generates a list which is then sent to the prediction function in one go.
import base64
import json
from sklearn.externals import joblib
PREP1_FILE_NAME = '/opt/PreProc1_MyModel.joblib'
PREP2_FILE_NAME = '/opt/PreProc2_MyModel.joblib'
MODEL_FILE_NAME = '/opt/MyModel.joblib'
def predict(data):
# Load the model pre-processors
pre1 = joblib.load(PREP1_FILE_NAME)
pre2 = joblib.load(PREP2_FILE_NAME)
clf = joblib.load(MODEL_FILE_NAME)
print("Loaded Model and pre-processors")
# perform the prediction
X1 = pre1.transform(data)
X2 = pre2.transform(X1)
output = dict(zip(data, clf.predict(X2)[:]))
return output
def lambda_handler(event, context):
predictList = []
for record in event['Records']:
# decode the base64 Kinesis data
decoded_record_data = base64.b64decode(record['kinesis']['data'])
# load the dynamo DB record
deserialized_data = json.loads(decoded_record_data)
predictList.append(json.loads(deserialized_data['textblob']))
result = predict(predictList)
return result
Once again, the function will be zipped and then published. It is assumed the underlying role has already been created:
zip MyModel20190104v1_lambda_function.zip lambda_function.py
aws lambda create-function --function-name MyModelInference --runtime python3.6 --handler lambda_function.lambda_handler --role arn:aws:iam::xxxxxxxxxxx:role/MyModelInference_role --zip-file fileb://MyModel20190104v1_lambda_function.zip
Link the layers
The layers need now to be linked to the previously generated function using the ARNs:
aws lambda update-function-configuration --function-name MyModelInference --layers arn:aws:lambda:eu-west-1:xxxxxxxxxxx:layer:MyMLfunction_layer1:1 arn:aws:lambda:eu-west-1:xxxxxxxxxxx:layer:MyMLfunction_layer2:1
Here the initial “version 1” of the layer is used, which is visible with the number after the colon.
Update (only) the model layers
If a new and improved version of the model is generated, it has to be uploaded again:
zip MyMLfunction_layer2_model20190105v1.zip *.joblib
aws lambda publish-layer-version --layer-name MyMLfunction_layer2 --zip-file fileb://MyMLfunction_layer2_model20190105v1.zip --compatible-runtimes python3.6
and the layer configuration of the function has to be updated:
aws lambda update-function-configuration --function-name
MyModelInference --layers arn:aws:lambda:eu-west-1:xxxxxxxxxxx:layer:MyMLfunction_layer1:1 arn:aws:lambda:eu-west-1:xxxxxxxxxxx:layer:MyMLfunction_layer2:2
After which step, the new model is deployed with our ML inference lambda function.
Execution and cost observations
As mentioned in the introduction to this article, we did some investigation regarding execution duration and cost. This kind of analysis is essential in most projects and is a requirement if you are following the AWS Well-Architected Framework.
In our use case the data ingest is based on batch process and occurs only a few times a day. At each ingest 50,000 data elements (Kinesis events) will be generated and therefore multiple short peaks of 50k predictions each have to be executed during the day.
Execution time
The function was triggered with different batch sizes of 1, 10 and 100 to see the general runtime difference.
- 1 prediction: Average runtime 3803 ms, billed duration: 3900 ms, Max Memory Used: 151 MB
- 10 predictions: Average runtime 3838 ms, billed duration: 3900 ms, Max Memory Used: 151 MB
- 100 predictions: Average runtime 3912 ms, billed duration: 4000 ms, Max Memory Used: 151 MB
The loading and initialisation time is of course the limiting factor as the overall runtime doesn’t change much with more predictions. In this case we would select a batch size of 100. For future investigations, we will also look how we can run the function in more optimized manner, maybe with a custom runtime, to bring this initialisation duration down and also make smaller batch sizes more effective.
Execution cost
As stated at the beginning, the mainstream ML deployment option in AWS is to host the model via Sagemaker. If the smallest instance size ml.t2.medium is chosen, an hourly cost of $0.07 is billed which would be a monthly fee of $50.40 for a 24/7 runtime, so this is our lower limit for comparison, since for higher loads more powerful and costly instances have to be used.
With AWS Lambda, a free tier is available, and with our chosen runtime size of 192MB this would be 2,133,333 seconds. After this free tier, a price per 100ms of $0.000000313 applies.
Assuming now a function execution of 4s with any batch size between 1 and 100, we come to a cost of $0.0000124 per execution.
Taking the single ingest of 50000 elements would mean that such a batch costs:
- Batch size 1: 50000 x $0.0000124 / 1 = $0.62 per ingest
- Batch size 10: 50000 x $0.0000124 / 10 = $0.062 per ingest
- Batch size 100: 50000 x $0.0000124 / 100 = $0.0062 per ingest
Let’s compare how many ingest with batch size 100 we can do per month until we reach the costs of the smallest hosted ML instance of $50.40:
$50.40 / $0.0062 = 8129 ingests
This would be 271 ingests per day or 11 ingest per hour before our lambda function would be more expensive.
Conclusion
Executing ML inference using a full serverless approach can be very effective. If the execution time can be limited and the right batch size is used, it is more affordable than a permanently hosted model and endpoint. Additionally, going serverless even allows handling peaks in load automatically without custom scaling logic/config or adapting the hosted instance size.
Using a layered approach allows us to independently and easily deploy new models without touching and deploying the complete code. Of course, it is also easy to revert back to a prior version.
Building via docker containers allows us to have a consistent runtime for the functions. As Kelsey Hightower has shown during his KubeCon 2018 keynote: Kubernetes and the Path to Serverless (Recommended to watch!) it is possible to extract a docker image layer and upload it to generate the custom runtime. I guess we will see more in this space soon!